PostgreSQL 두서없이 일단 정리하기(1) - 내부구조, 트랜잭션
PostgreSQL 의 데이터 살펴보기
해당 내용은
https://www.youtube.com/watch?v=lNLQDo-QcTg&list=PL4i1lIrXNArb_MUXFbdoCEO5_eWnPt3Fu
Youtube 재생목록을 참고해서 추가적으로 내가 학습해나갔다. (Notebook LM 으로 PostgreSQL 내용을 정리해서 올린 재생목록)
PostgreSQL 내부 들여보기
데이터의 큰 그림
데이터베이스 클러스터 : 하나의 PostgreSQL 서버 인스턴스가 관리하는 여러 DB 를 모은 것.
(서버가 실행되면, 메모리(Shared Buffer) 와 백그라운드 프로세스들이 구동)
클러스터 - Database - Schema - Table
논리적 주소, 물리적 주소
비용 절감, 안정성 두가지 측면에서 접근할 수 있다.
- 책을 어떤 주제로 분류 - 논리적 주소
- 실제 어느 건물 몇 층에 꽂아두는지 - 물리적 주소
이 차이점이 PostgreSQL 을 유연하게 만들어준다.
Schema 는 논리적인 주소
Table Space 는 물리적인 주소
- 비용 효율 : SSD(Hot Data), HDD(Cold Data) 를 나눌수 있다.
도서관에서 제일 잘 나가는 베스트 셀러는 입구에 위치시켜야 한다.
-> 논리적으로, 제일 인기 많은 요소를 제일 비싼 SSD 에 넣어서 성능을 올릴수 있다.
- 안정성 : 데이터 파일과 WAL(Write Ahead Log, 트랜잭션 로그) 파일을 물리적으로 다른 디스크에 저장하기도 한다.
디스크 I/O 경합 줄이고, 데이터 디스크 깨져도 로그는 살릴수 있다.
데이터 기본 단위, 릴레이션
릴레이션은 다소 혼동을 줄 수 있는 용어, ‘관계’ 라는 의미는 모호함
PostgreSQL 의 태생 자체가 연구실에서 시작된 프로젝트라서 학술적인 배경이 남아있음
Relation?? 표처럼 되어있는건 그냥 Relation 이라고 생각
-> 행과 열로 구성된 모든것들 (테이블, 인덱스 등)
Forks
하나의 릴레이션은 물리적으로 ‘Fork’ 라 불리는 여러 전문화된 파일에 나뉘어 저장
- main : 실제 데이터 파일
- fsm : free space map, 어디에 빈공간 남았는지 알려주는 파일
- vm : visibilty map, 이 페이지의 데이터가 지금 보이는게 맞는지 (모든 트랜잭션에게 보여도 되는지) 알려주는 파일
추가로, vm 은 성능에 도움도 준다. ⭐
- Index Only Scan
다른 DB 는 인덱스에 필요한 데이터가 다 있는 커버링 인덱스 경우, 테이블을 안보고 인덱스만 읽고 끝낸다.
하지만, PostgreSQL 은 MVCC 때문에 이게 어렵다.
인덱스에는 xmin, xmax 정보가 없다.
-> 데이터를 찾아도, 이 데이터가 보여도 되는 데이터인지 or 지워진 데이터인지 를 명확히 알 수 없다.
-> 기존에는, 무조건 테이블 영역을 가서 실제 데이터의 xmin, xmax 를 확인해야 했다. (Random I/O 발생 -> 성능 저하)
VM 은 비트맵 지도이다. 각 테이블 페이지마다 2개 비트를 사용해 상태를 표시한다.
- All-Visible : 페이지에 있는 모든 데이터가 확정되어서, 모든 트랜잭션에 다 보여도 상관없음 - 죽은 튜플 X, 진행 중 트랜잭션 X
- All-Frozen : 페이지는 Vacuum Freeze 까지 끝남, Transaction ID 랩 어라운드 방지용
VM 을 통해, 전부 다 보이는 데이터 -> 테이블 스킵! 이 가능해진다.
거대한 데이터를 다루는 법, TOAST
데이터를 압축해서 크기를 줄이거나, 여러 조각으로 잘게 썰어서 보관하는 기술
-> TOAST!
- TOAST : The Overised Attribute Storage Technique, Postgres 값을 효율적으로 저장하고, 관리하기 위해 사용하는 자동 메커니즘
- 기본적으로, 내부 알고리즘을 사용해 값을 압축한다.
- 압축해도 값이 크면, 해당 값을 별도 테이블(TOAST 테이블)로 이동하고 원래 테이블에 포인터를 남겨 둔다.
사용자 눈에는 하나도 보이지 않는다. 장점이자, 단점
- integer, float, timestamp 같은 고정 길이 데이터 유형은 페이지 내 들어가므로 TOAST 적용을 받지 않는다.
- json, jsonb, 큰 text, varchar, PostGIS 등이 적용 대상
- 대략 2000 바이트를 넘기면 자동 동작
전략에 따라 동작을 미세 조정도 할 수 있다. (컬럼별 설정가능)
- PLAIN : 절대 압축하지 말고, TOAST 도 쓰지말기 - 8KB 넘으면 에러 발생
- MAIN : 압축 하되, TOAST 테이블 보내는건 최대한 미루기
EXTENDED : 기본값, 압축도 하고 TOAST 테이블로 보내기
- TOAST 된 데이터에 액세스하면 오버헤드가 추가될 수 있다. (특히, 데이터가 외부에 저장되어 있으면 더욱 오버헤드 발생)
DB 트랜잭션의 비밀
가장 단골 질문 :
계좌 이체 중 돈이 사라진다면.
- 인출 :A 계좌에서 돈을 인출
- 입금 : B 계좌에 돈을 입금
이 사이에는 사실 일관성이 깨진다.
인출을 할때, A 계좌의 돈은 인출되었지만 B 계좌에는 입금이 되지 않았기 때문이다.
=> 트랜잭션이 나타난 이유
트랜잭션
데이터베이스 상태를 올바르게 변경하는 일련의 작업. 원자성, 격리성
=> 근데, 이런 로직은 하나만 일어나는 것이 아니다. 수천, 수만건이 동시에 일어날 수 있다!! (동시성 이상현상)
Lost Update
두 트랜잭션이 같은 행을 읽고
한 트랜잭션의 변경 사항을 무시하고 다른 트랜잭션이 같은 행을 수정할 때 발생한다.
사실, 이건 DB 에서 뿐만이 아니라 Application 단에서도 나타날 수 있는 현상이다.
데이터 두개를 동시에 조회해서, 화면에서 수정 요청을 보낼 때 이전 요청의 값을 덮어씌울 수 있다.
FOR UPDATE로 비관적 락 구문으로 처리
Dirty Read
한 트랜잭션이
다른 트랜잭션의 아직 확정되지 않은 변경 사항을 읽을 때 발생한다.
다른 트랜잭션이 롤백이 발생하면, 문제가 발생한다!
추가로, PostgreSQL 은 아키텍처의 특성상 Dirty Read 가 절대 발생하지 않는다.
(MVCC 때문에 커밋되지 않은 데이터는 아예 보일수가 없다. - 트랜잭션 ID 가 다르므로)
Non Repeatable Read
한 트랜잭션이 동일한 행 두 번 읽는 동안
다른 트랜잭션이 해당 행을 수정, 삭제하고 확정할 때 발생
즉, 이전과 이후 조회한 값이 달라진다.
Phantom Read
한 트랜잭션이 동일 질의 두 번 실행하는 동안
다른 트랜잭션이 조건에 맞는 새 행을 추가하고 확정할 때 발생
3개의 계좌 제한이 있을때 2개여서 1개를 만들었다고 가정해보자.
이때, 다른 곳에서 1개의 계좌를 만들어주면..?
-> 4개가 된다.
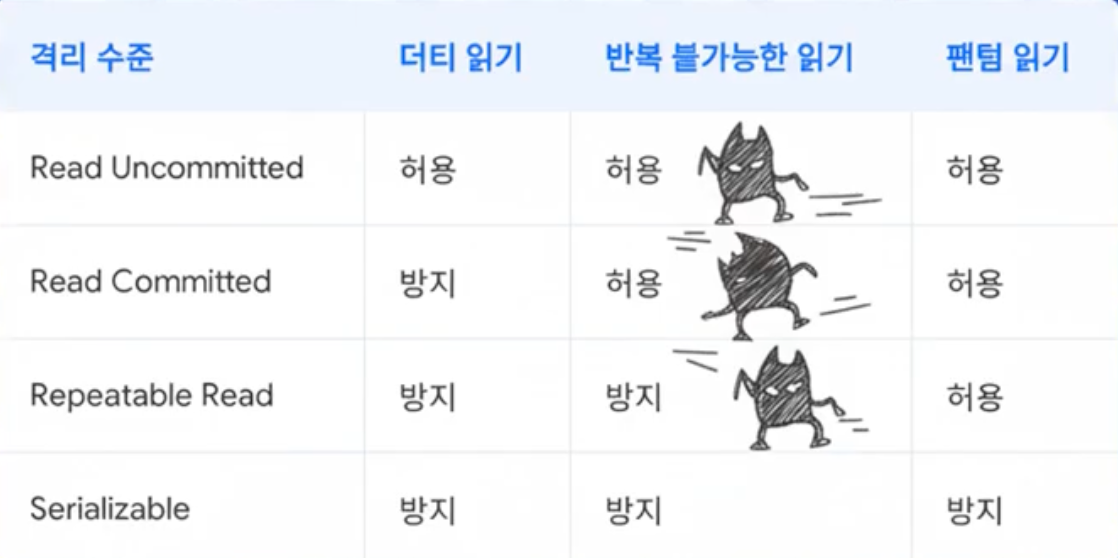
격리 수준에 따라, 이를 보장해주거나 허용해준다.
하지만, Serializable 을 하면 너무 완벽하기에 ( 행 단위로 꼼꼼히 처리 ) 속도가 느리다.
=> 우리는 이 속도와 안정성 사이에서 결정을 내려야 한다.
(대부분의 RDBMS 는 Read Committed 를 기본으로 처리, 심각한 문제를 일으키는 Dirty Read 를 방지하므로 )
데이터베이스 해부
데이터는 어디로 가는건가.
페이지
실제 데이터들과 이를 관리하기 위한 메타데이터를 포함하는 디스크 상 고정 크기 블록
- 기본값은 8KB
5가지 핵심 요소로 구성되어 있다.
- 페이지 헤더 : 페이지의 체크섬, 각 부분의 크기 같은 정보
- 아이템 포인터 : 페이지 내 튜플의 위치를 가르키는 포인터 배열, 위에서 부터 아래로
- 빈 공간 :
- 아이템 : 튜플, 아래에서 부터 위로
- 특수 공간 : 일부 인덱스에서 부가 정보 저장하는데 사용
=> 데이터가 쌓일수록 아이템 포인터와, 아이템 둘 사이 공간이 줄어든다.
(빈 공간은 Free Space 라고 한다.
데이터를 바로 찾는게 아닌, 포인터를 통해 찾기 때문에 현명하게 동작한다.
(데이터 위치가 바뀌어도, 상관없이 포인터만 찾아가면 된다.)데이터를 쓰고 지우고를 반복하면, 페이지 내부 ‘빈 공간’ 이 조각으로 생겨난다.
-> 파편화!, 정리도 해야함
지워지지 않는 데이터
PostgreSQL 은 데이터를 왠만해선 덮어씌우거나, 지우지 않는다.
즉, 기존 데이터를 바꾸는게 아닌 완전히 새로운 튜플을 만드는 것이다.
모든 튜플에는 xmin, xmax 라는 값이 있다. (transaction id)
- xmin : 이 버전이 언제부터 유효한지를 나타냄
- xmax : 이 버전이 언제까지 유효한지를 나타냄
-> 이를 통해, 데이터의 유효기간을 나타낼 수 있다.
776번 트랜잭션이 새로운 데이터를 삽입했다면?
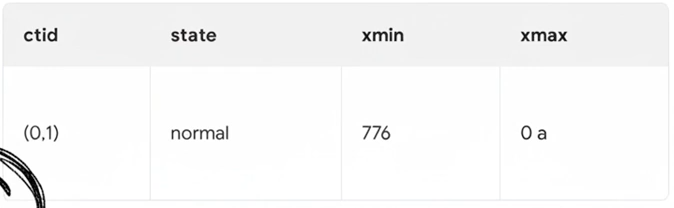
새로운 데이터가 생성된다. ( xmin 은 776, xmax 는 0 )
이 데이터를 778번 트랜잭션이 업데이트 한다면?
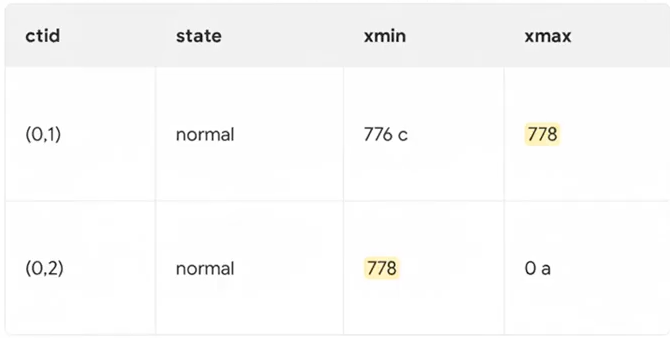
- 기존 데이터의 xmax 가 778번으로 채워진다
- 새로운 데이터가 생성된다. ( xmin 은 778번, xmax 는 0 )
그러면, 지우지 않고 새 버전만 계속 만들어서 테이블 크기가 무한히 커지는건가?
-> 이를 위해, VACUUM 이 필요하다. (더 이상 아무도 보지 않는 옛날 버전 Dead Tuple 찾아서 재사용하라는 표시를 남김)
-> 이 청소가 제때 안되면 테이블이 뚱뚱해져 조회 성능이 느려진다 - ‘Bloat’ 현상
왜 옛날 데이터가 필요한가
굳이 삭제를 하지않고, 데이터를 새로 생성하는 식으로 처리를 할까? ( 오히려, 더 불편한거 아닌가? )
-> 다중 버전 동시성 제어 (MVCC) 를 구현하기 위해 이 방식을 사용한다
하나의 행을 여러 버전으로 관리해서 서로 방해받지 않고 동시 읽고, 쓸 수 있게 한다.
- 일종의 데이터 시간 여행이 가능 : 작업이 잘못 되면, 해당 버전을 무시하면 로직이 끝
- 트래픽 정체 X : 여러 사람이 동시에 동일 데이터를 사용해도, 서로 방해하지 않는다
- 데이터 무결성 보장 : 데이터를 변경하다 중간에 에러가 나도, 그 데이터를 사용하지 않으면 끝이다
성능과 데이터 검색에 미치는 영향
데이터를 검색하려면?
- 인덱스라는 거대한 목차부터 검색해 페이지를 찾음
- 페이지에서 xmin, xmax 를 기반으로 보여줘야 하는 데이터만 보여준다