RabbitMQ VS Kafka
This post compares the differences and characteristics of RabbitMQ and Kafka and suggests suitable use cases.
[Reference Materials]
- Video: [10 Minutes Tech Talk] RabbitMQ vs Kafka
- Blog:
Introduction
In modern server application architectures, a messaging system is inevitable.
The purpose can vary, such as separating logic to improve response speed, ensuring stability and execution, and communicating with other application servers. Many development teams will worry about which technology to use.
I too started with the question, “Why does our team use RabbitMQ instead of Kafka?” In that process, I found my own answers that I wanted to share.
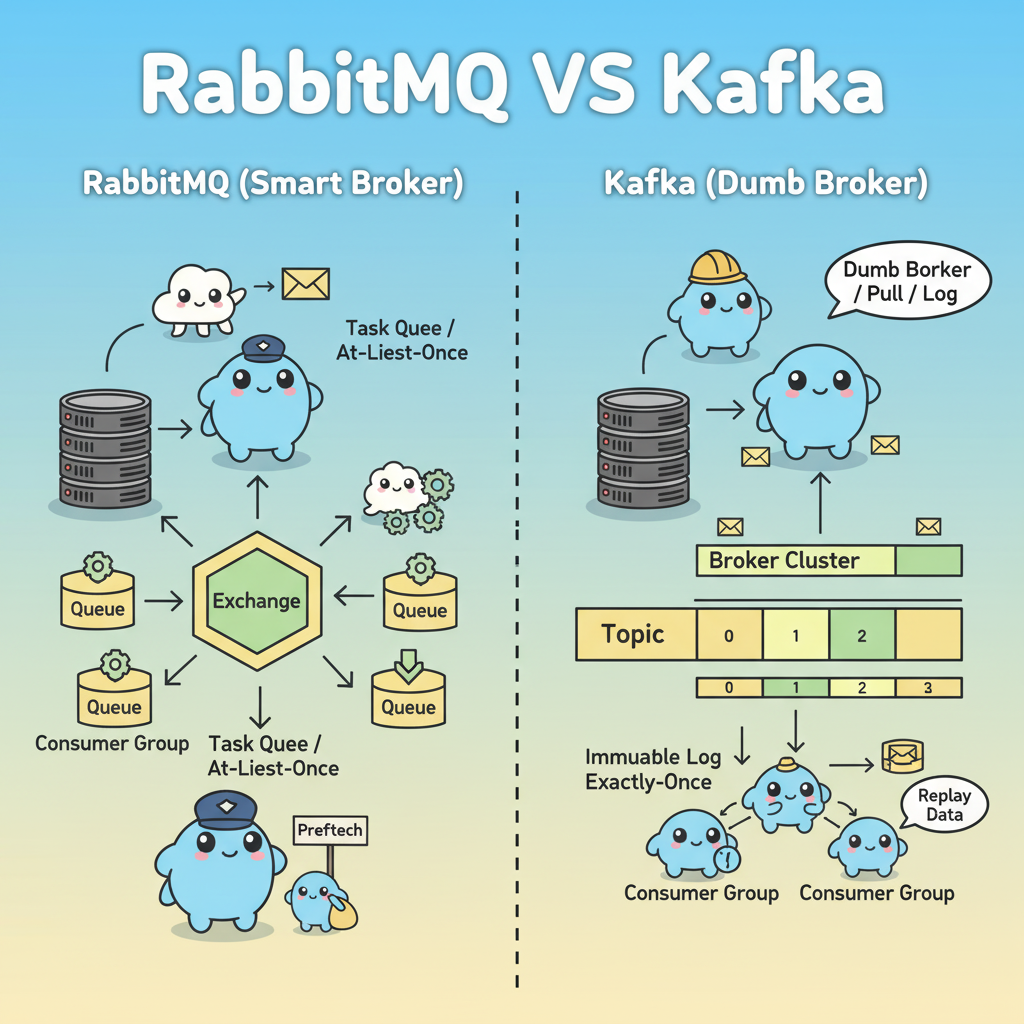
RabbitMQ (Smart Broker & Dumb Consumer)

RabbitMQ is a message broker that implements AMQP (Advanced Message Queuing Protocol) and also provides the MQTT protocol. The core idea is that the broker (RabbitMQ) handles most of the routing, message storage, and delivery logic.
AMQP? Advanced Message Queueing Protocol: A standard protocol for message-oriented middleware. It ensures reliable messaging between different systems and applications.
- Interoperability: Enables communication between systems developed on different languages and platforms.
- Reliability and Trustworthiness: Ensures messages are delivered without loss, with message acknowledgment (ACK), persistence, and transaction support.
- Flexible Routing: Routing through Exchange - producers send to Exchange, and Exchange distributes messages to the appropriate queue according to set rules.
- Producer: Creates messages and sends them to the Exchange.
- Exchange: A set of routing rules that decides which Queue to send the received messages from the Producer to (does not store the message itself).
- Direct Exchange: Sends messages to the Queue matching the exact routing key (unicast).
- Topic Exchange: Sends messages to the Queue matching a certain pattern in the routing key (multicast).
- Fanout Exchange: Sends messages to all queues bound to it (broadcast).
- Headers Exchange: Routes based on message header attributes.
- Queue: A buffer that stores messages until the consumer retrieves them.
- Binding: A rule connecting Exchange and Queue. (“This Exchange sends messages to this Queue according to the routing rules”).
- Consumer: Retrieves messages from the Queue and processes them.
Core Flow: Producer → Exchange → (Binding Rule) → Queue → Consumer
Smart Broker
- Complete control over message flow: The broker decides where to send messages and routes them according to Exchange & Binding rules.
- Tracks consumer state: Continuously tracks whether the consumer is connected to any queue and whether messages are properly processed.
- Sends messages to consumers: Pushes messages to consumers; consumers adjust the amount they can handle with prefetch.
- Offers various features: Provides functionalities such as Dead Letter Exchanges, message TTL, priority queues.
Dumb Consumer
- Focus on simple roles: The consumer connects to a designated queue to receive and process messages and only sends completion signals.
- No need to know about routing: The consumer doesn’t need to consider how the message arrived in its queue.
=> The post office (broker) categorizes and addresses all letters while the mail carrier (consumer) delivers the letters assigned to their zone.
Kafka (Dumb Broker & Smart Consumer)

Kafka is a distributed streaming platform that treats messages as a consecutive stream of immutable logs. The broker stores and manages data, with the consumer handling complex routing logic.
- Broker: Kafka server instance that stores and manages messages and forms a Cluster when gathered with other brokers.
- Receives messages from Producers, assigns offsets, and stores messages on disk.
- Responds to partition read requests from consumers and sends messages recorded on disk.
- One serves as the cluster’s controller, assigning partition responsibilities to each broker and monitoring their proper operation.
- Cluster: Composed of multiple brokers, providing data replication, fault tolerance, and high availability.
- Adding server brokers within the cluster increases the handling of message reception and delivery.
- Can be performed online without affecting overall system usage (easily scale from a small operation to accommodate large traffic amounts).

- Topic: A category or feed name to separate messages. Similar in role to Exchange in RabbitMQ, but directly stores messages.
- Similar to a DB table or a folder in a file system.
- A Topic is composed of multiple partitions.
- Partition: An append-only log that allows for distributed storage of Topic data across multiple brokers and increases throughput.
- Order within a partition is guaranteed. - No order guarantee between different partitions.

- Producer: Creates messages (records) and sends them to a specific Topic.
- Consumer: Retrieves and processes messages from the Topic.
- Subscribes to one or more topics and reads messages in the order they were created, keeping track of message locations via offset on a partition basis.
- Offset: A unique serial number (ID) each message has within a partition. Consumers use offsets to track and control where they have read up to.
- Commit Offset: An offset confirming the consumer has processed “up to here.”
- Current Offset: An offset confirming “where they have read up to.”
- Consumer Group: A group of one or more consumers where each partition of a Topic is allocated to only one consumer within the group.
- Each consumer can read messages from different partitions of the topic they are responsible for.
- Adding consumers extends message consumption performance.
Adding more consumers than the number of partitions within a topic is meaningless.
Core Flow: Producer → Topic (Partition) → Consumer (Consumer Group)
Dumb Broker
- Concentration on role as high-performance file storage: Brokers quickly add and store messages at the end of topic partitions.
- No message state tracking: Brokers don’t consider which consumer read which message, just storing them for the set retention period.
- No complex routing: Brokers store messages in the topic/partition designated by the producer without redistributing messages on their own.
Smart Consumer
- Manages reading locations by themselves: Consumers record & manage which part of the topic’s partition they read up to.
- Actively fetch data: Pull, consumers actively request and fetch data from brokers.
- Responsible for partition assignment logic: The consumer group’s client library handles decision logic on which partition each consumer will manage.
=> A large library (broker) only continuously shelves books (messages) in bookcases (partitions), while readers (consumers) visit the library, remember what they have read (offset), and take the next book to read.
The Gemini analogy is good…!
Common Misunderstandings
There may be misconceptions that the two systems have similar structures and differ only in performance (or that RabbitMQ is a message system not used), but understanding these concepts clearly is essential to grasp the architectural philosophy differences between the two systems.
Fanout: A pattern where one message is delivered as identical copies to several independent consumers.
1. Kafka’s ‘Fanout’ is not Simple Broadcast
One of the most common misconceptions is the binary view that Kafka is Pub/Sub and RabbitMQ is Work-Queue. In fact, Kafka elegantly integrates these two models through the concept of Consumer Groups.
Inter-Group: Pub/Sub (Fanout/Broadcast): Different consumer groups can still independently consume the entire message stream even if they subscribe to the same topic. EX) When there is a topic called
order-events, groups likeInventory Management Service(Group A) andData Analysis Team(Group B) can subscribe to it separately. In this case, both groups can receive and process all messages fromorder-eventsfrom start to finish independently.Intra-Group: Work-Queue (Distributed Processing): Within a single consumer group, the story changes. Consumers within the group divide and process the partitions of the topic. (A partition is assigned to only one consumer within the group). If there are 4 partitions in a topic and 4 consumers in the group, each consumer will be responsible for one partition and process messages. -> This distributes workloads and increases throughput, matching the ‘work queue’ model.
Core: Kafka applies both methods through Consumer Groups: data replication/broadcast between different systems and distributed task processing within a single system to maximize throughput.
2. Philosophy on Message Retention: ‘Log’ or ‘Queue’?
The fundamental difference between the two systems lies in how they handle messages.
Kafka: Data is an ‘Immutable Log’ Kafka does not immediately delete messages once consumed. Messages are safely stored in the topic until the retention period (e.g., 7 days) or capacity is reached. Consumers only manage an Offset that indicates ‘where they have read up to’.
- Message Replay & Time Travel:
- If a bug occurs in a consumer? Correct the code, then rewind the offset to reprocess all data.
- Introducing a new system using the messages? Retrieve all events from the beginning of the topic to reconstruct state.
- Multipurpose Data Hub: A single event stream can be consumed multiple times by various consumers for different purposes such as real-time dashboards, batch analysis, or model training, at their own pace.
- Message Replay & Time Travel:
RabbitMQ: Data is ‘Transient Task’ In traditional RabbitMQ, messages are ‘tasks to be processed.’ Once a consumer retrieves a message and confirms it has been processed (ack), the message is permanently removed from the queue.
This method features:
- Optimized for Task Queues: Efficiently manages tasks like ‘Send an email,’ ‘Generate an image,’ or ‘Optimize an image,’ which do not need to be preserved after being processed.
- Error-focused Retention: Message TTL (Time-To-Live) or Dead Letter Exchange (DLX) are functions for when messages are not successfully processed. (Permanent retention is more for exception handling and retry logic, not the core purpose)
Note: RabbitMQ, adapting to the times, introduced a new queue type called Streams. It provides offset-based non-destructive consumption similar to Kafka, operating like logs. However, RabbitMQ is fundamentally used for the ‘consume-remove’ pattern.
3. RabbitMQ’s Fanout Relies on ‘Exchange’
RabbitMQ fanout operates differently from Kafka’s. The core of RabbitMQ’s routing capabilities lies in the Exchange.
Producers send messages to Exchanges rather than directly to a Queue. Based on its type and rules, the Exchange determines which queue to send messages to.
fanoutExchange: Copies and sends messages to all queues bound to it. It’s the purest form of broadcast model.topicExchange: Matches routing keys with binding patterns using wildcards (*,#) and sends messages to queues meeting the criteria (multicast).directExchange: Sends messages only to queues whose binding key exactly matches the routing key (unicast).
Core: In RabbitMQ, smart brokers (Exchange) interpret routing rules intelligently to distribute messages. In contrast, in Kafka, producers specify topics, and smart consumers group together to fetch messages.
RabbitMQ vs Kafka: 7 Key Comparison Points
Now, let’s delve deeper into the specific functions and characteristics of the two systems across seven core themes.
1. Message Retention & Replay: Differing Outlooks on Data
- Kafka: Permanent Log, Infinite Replay Capability

Philosophy: Kafka regards the data as ‘a record of facts’ rather than ‘temporary messages.’ Messages are stored based on
retention.ms(time) orretention.bytes(capacity) settings.- Offset Reset (Replay): Consumers can always enable
auto.offset.reset = 'earliest'to read all events from the beginning of a topic. (This permits infinite possibilities like debugging and recovery, constructing states for new services, A/B testing) - Log Compaction: When set with
cleanup.policy=compact, Kafka retains only the latest value for each message key instead of storing all messages of a topic.Refer to the Kafka Log Compaction documentation.
- Offset Reset (Replay): Consumers can always enable
RabbitMQ: Removal-based Task Queue
- Philosophy: RabbitMQ’s default model places priority on stable task delivery, treating messages as tasks queued for processing, removing them upon successful confirmation
(ack). - Limited Replay: Once a message is
acked, free replay as in Kafka is not viable. To reprocess in case of failure, it either goes to Dead Letter Exchange (DLX) or is re-queued via consumernackorreject. - Stream Queue (Streams): Starting RabbitMQ 3.9, stream queue allows operations similar to Kafka’s log operations. This permits non-destructive consumption and fanout distribution of large data. (But these complement RabbitMQ’s traditional model, where Kafka is, unsurprisingly, further matured)
- Philosophy: RabbitMQ’s default model places priority on stable task delivery, treating messages as tasks queued for processing, removing them upon successful confirmation
2. Ordering & Parallelism: Guarantees and Trade-offs
- Kafka: Strict Order Guarantee by Partition
- Operation: Within a single partition, Kafka guarantees the order of messages absolutely. Messages are logged in the order producers send them, and consumers read in that same order.
- Trade-off between Parallelism and Order: Increasing the number of partitions to boost throughput enhances parallel processing while sacrificing order across partitions.
- Key-based Partitioning: For crucial order guarantees, message keys must be utilized. (For instance, using
user_idas key ensures alluser_idrelated events are sent to the same partition via hash calculation, ensuring all events are processed sequentially.)
- RabbitMQ: Uncertainty in Order with Competitive Consumer Environment
- Default Operation: While the queue structure is FIFO (First-In-First-Out), when multiple consumers subscribe to a single queue to competitively retrieve messages, the order of message processing is not ensured. EX) Consumer A retrieves message 1 and Consumer B retrieves message 2 almost simultaneously and B processes faster, message 2 might be processed before message 1.
- Order Guarantee Method: It is possible to force order by activating only one consumer per queue. (This compromises parallelism, reducing productivity)
Controlling order in RabbitMQ is deceptively tough.. Let messages trigger subsequent messages to ensure order.
3. Delivery Guarantees: Promises against Data Loss and Duplication
- Kafka: Supports Exactly-Once Delivery
- At-least-once: Default setting allows re-consumption and duplication if failure occurs before consumers confirm and commit offsets.
- Exactly-Once (EOS): Supported since Kafka 0.11 through Idempotent Producer and Transactions.
- Idempotent Producer: Eliminates duplicates despite retries by assigning unique IDs to each message.
- Transactions: Groups several operations across multiple topic/partitions atomically, enabling a complete Read-Process-Write pattern for EOS.
Refer to: Exactly-Once Semantics Are Possible: Here’s How Kafka Does It
- RabbitMQ: Defaults to At-least-once; Exactly-once falls on Application
- At-least-once: Consumers facing disconnection after message retrieval and processing before broker acknowledgment may cause re-distribution and duplicates.
- At-most-once: Utilizing
auto-ackmode can result in message loss upon processing failure since the broker considers prompt reception as acknowledgment. (Requires careful application) - Absence of Exactly-once: Lacking direct EOS support at protocol/broker level. Application-designated idempotency logic must implement EOS.
But, At-least-once settings are far from bad. It essentially guarantees that specific logic desired by the consumer will occur. Even if one consumer fails, another ensures it is processed correctly. This means another message can fully integrate the process outcome into the DB.
4. Flow Control & Backpressure: Who Sets the Pace?
- Kafka: Consumer-led Pull Basis
- Philosophy: Consumers retrieve broker data via Pull, matching their processing capacity. Data is transmitted only upon consumer’s
poll()method call. - Backpressure: This model, by nature, creates backpressure. When busy, the consumer refrains from
poll(), leaving the data to await at the broker. (Allows fine-tuning of consumption speed via options likemax.poll.records(maximum number of messages fetched at once) andfetch.min.bytes(minimum data accumulation for response).
- Philosophy: Consumers retrieve broker data via Pull, matching their processing capacity. Data is transmitted only upon consumer’s
- RabbitMQ: Broker-led Push Basis + Prefetch
- Philosophy: The broker pushes messages to consumers. This can overwhelm consumers as messages are sent regardless of readiness.
- Backpressure (Prefetch): Set the
prefetchvalue (QoS - Quality of Service) to resolve this. Limits the number of messages the broker sends to a consumer if they’re already processing a certain number, based on theprefetchsetting.
Setting RabbitMQ’s
prefetchvalue is critical for performance and stability. A setting too small incurs frequent network round-trips reducing throughput, while too high risks consuming consumer memory. (This can be crucial when certain domains, like an AI image generation logic using a GPU, require processing one task at a time;prefetch 1in such case)
5. Routing/Topology: ‘Smart Broker’ vs ‘Dumb Broker’
As the content has been previously covered, I’ll keep it brief.
- Kafka: Simple Topology, Smart Client
- Dumb Broker: Kafka brokers operate simply, storing messages in the sequentially designated topic partitions by producers (with no complex routing logic).
- Smart Clients: Primarily producers decide routing. They decide which topic and key to use to send messages and which partition to target. Consumers determine which topic to subscribe to.
- RabbitMQ: Flexible Routing, Smart Broker
- Smart Broker: RabbitMQ is adept at handling through Exchanges. Producers send messages to Exchanges, and the Exchange allocates them to appropriate queues based on configured types (
direct,topic,fanout,headers) and routing rules (binding). - Implementing Complex Workflows: They can easily construct sophisticated workflows at the broker level to send messages conditionally based on message content or simultaneously to multiple queues. (Dead Letter Exchange, Delayed Message Plugin can be combined for retry, delayed execution, etc.)
- Smart Broker: RabbitMQ is adept at handling through Exchanges. Producers send messages to Exchanges, and the Exchange allocates them to appropriate queues based on configured types (
6. Scalability & High Availability (HA): Scale Out and Data Replication
- Kafka: Perfect Horizontal Scale via Partitions
- Design: Kafka is designed as a distributed system from the start. Topics can be divided into multiple partitions and dispersed across several brokers in a cluster, ensuring horizontal scale-out for reading and writing burden.
- High Availability (HA): Each partition has a Replication Factor.
- One partition becomes Leader, handling read/write, while the rest are Followers, replicating the Leader’s data.
- In the event of a Leader broker failure, one Follower is automatically elected as the new Leader with minimal service downtime - failover.
- RabbitMQ: Modern HA through Quorum Queues and Streams
- Mirrored Queues: Formerly used mirrored queues, now avoided in favor of Quorum Queues due to Leader-Follower model restrictions and data reliability concerns.
- Quorum Queues: Introduced in RabbitMQ 3.8 and operates based on the Raft consensus algorithm. It ensures replication to a majority of the cluster nodes, offering reliability significantly above mirrored queues. It is recommended for cases where high availability and data safety are paramount.
- Stream Queues (Streams): For demanding throughput and scalability scenarios use. Streams can be sharded across multiple brokers, providing Kafka-like scalability.
Problems with the Leader-Follower Model?
- Bottleneck in writing: The message must reach leader queues first, waiting for follower replication and acknowledgment.
- Bottleneck in reading: Consumers can only connect to the leader for message retrieval. => Publishing and consumption traffic centers on a leader node.
7. Ecosystem & Tools: ‘Platform’ vs ‘Broker’
- Kafka: Data Pipeline Platform Kafka extends beyond mere messaging brokers and acts as a comprehensive data platform in itself.
- Kafka Connect: Framework connecting Kafka with hundreds of systems like databases, S3, Elasticsearch without coding.
- Kafka Streams / ksqlDB: Libraries and SQL engine stream-processing and analyzing Kafka topic data in real-time.
- Schema Registry: Manages data schemas to ensure data consistency and compatibility.
- RabbitMQ: Versatile Message Broker RabbitMQ feels more like a powerful broker tailored for specific purposes.
- Management UI: Offers an excellent web UI for visually monitoring and managing queue status, message flow, connections, etc.
- Federation / Shovel: Robust plugins to connect brokers across different data centers or environments.
- Diverse protocol support: Offers flexibility through plugins supporting various protocols like AMQP 0-9-1, AMQP 1.0, STOMP, MQTT.
When to Choose What..?
Reflective of AI-generated content and considerations on why our team uses RabbitMQ, it naturally might not hold true.
- “Do you need to reprocess past data?”
- Yes → Kafka: If data replay is necessary for event sourcing, data analysis, introducing new services, then choose Kafka.
- “Does each message need to be routed differently based on complex criteria?”
- Yes → RabbitMQ: If sophisticated routing based on message headers or routing key patterns is essential - Smart Broker.
- “Is the primary purpose to handle background asynchronous tasks?”
- Yes → RabbitMQ: For typical ‘task queue’ scenarios like email dispatch, image processing, etc., RabbitMQ offers a simple, intuitive solution (no need to retain messages).
- “Do numerous independent services require consuming the same event stream for different purposes?”
- Yes → Kafka: Constructing a ‘data hub’ or ‘event backbone’ where multiple teams, services consume the same data at their own pace - through Consumer Group model and message retention policy.
- “Is ultra-high throughput, like processing hundreds of thousands per second, mandatory?”
- Yes → Kafka: Optimized for handling large-scale stream data using disk-based sequential I/O - leverages technologies like Append-Only, OS-level page cache, Zero-Copy.
- “Do you require per-message TTL, delayed operations, or request-response (RPC) patterns?”
- Yes → RabbitMQ: RabbitMQ more maturely supports these advanced messaging patterns through plugins and similar configurations.
Conclusion
Don’t fall into the mindset of defaulting to Kafka for message queuing systems. It’s a decision demanding consideration of the company’s infrastructure, team technology, project requirements, and more.
Reasons why our team opts for RabbitMQ:
- To separate AI generation logic from the API server.
- Ensuring task completion.
- Current absence of need for large-scale handling and system setup plus no requirement for replay or storing messages.
These points lead us to use RabbitMQ.