어떻게 TaskScheduler 는 제 시간에 task 를 실행하나요? ( 부제. 현재 시간보다 이전인 작업이 바로 실행되는 이유 )
스프링이 태스크를 현명하게 등록하는 방법
주의⚠️ 해당 내용은 정말 템포가 깁니다. 틀릴수도 있습니다. 혹시, 잘못된 내용이 있다면 댓글로 또는
joyson5582@gmail.com로 남겨주세요!
현재 저희 프로젝트 는 TaskScheduler 를 통해 지정된 시간에 방 매칭이 자동으로 되게 하고 있습니다.
스프링은 어떻게 자동으로 지정된 시간에 요청이 수행되게 하는걸까요? 놀랍게도 스프링은 크게 코드를 작성하지 않고 기존 자바 코드를 통해 이를 구현했습니다.
그러면
- 테스크가 지정된 시간에 수행되게 등록
- 태스크가 지정된 시간에 실행되게 동작 두가지 에 대해서 살펴보겠습니다.
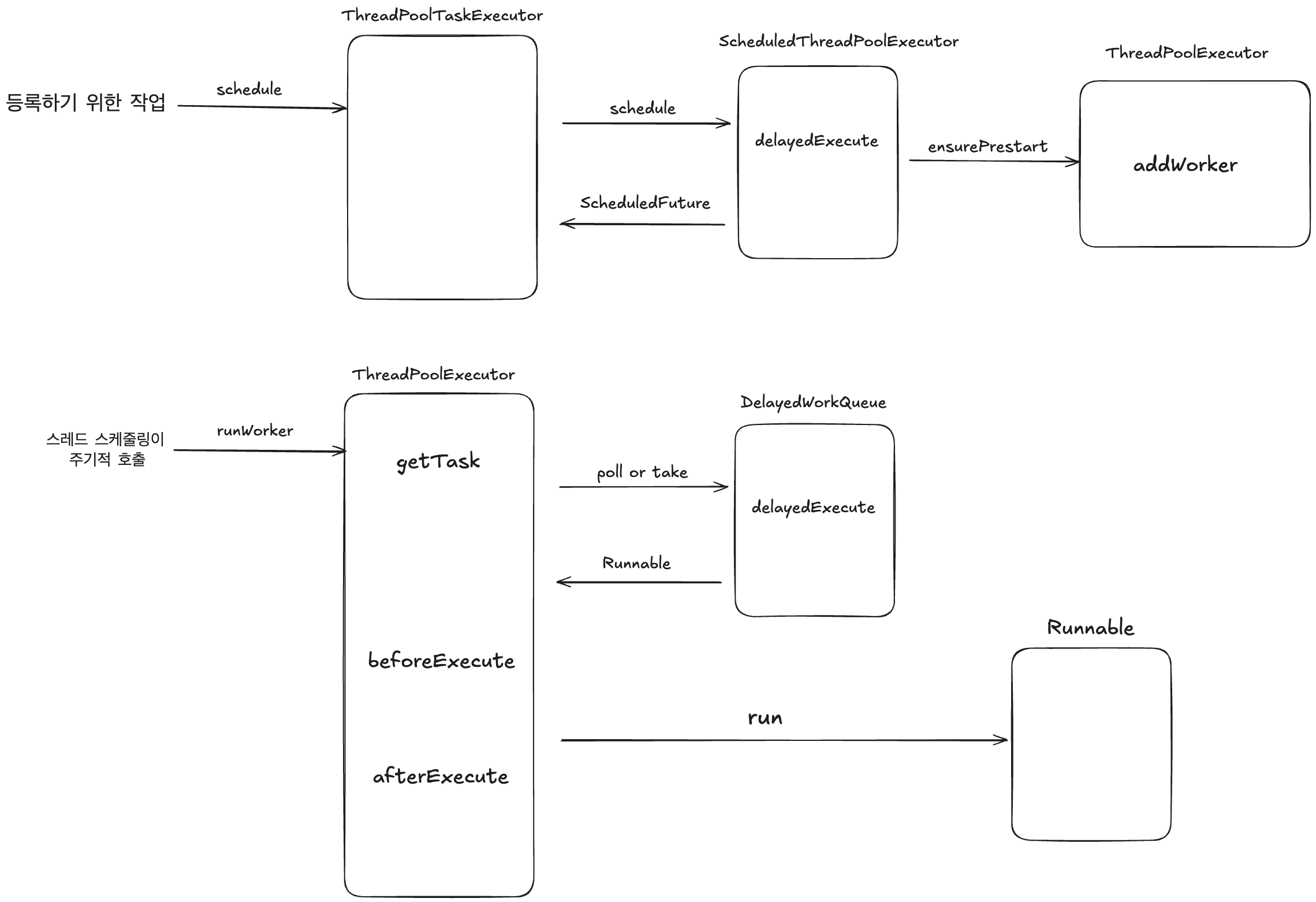
태스크가 지정된 시간에 등록
ThreadPoolTaskScheduler.schedule
package org.springframework.scheduling.concurrent; 에 위치해있는 클래스입니다. - 공식 문서
1
2
3
4
5
6
7
8
9
10
11
@Override
public ScheduledFuture<?> schedule(Runnable task, Instant startTime) {
ScheduledExecutorService executor = getScheduledExecutor();
Duration delay = Duration.between(this.clock.instant(), startTime);
try {
return executor.schedule(errorHandlingTask(task, false), NANO.convert(delay), NANO);
}
catch (RejectedExecutionException ex) {
throw new TaskRejectedException(executor, task, ex);
}
}
스레드를 실행할 ScheduledExecutorService 서비스를 가져옵니다. - 기본으로, ThreadPoolTaskScheduler 를 가져옵니다. 시간의 차이를 구한 후, 나노초로 변환하여 매우 정밀하게 동작하게 해줍니다. 그 후, 스케줄을 등록합니다.
ScheduledThreadPoolExecutor - schedule
package java.util.concurrent; 에 위치한 클래스입니다. - 공식 문서
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<Void> t = decorateTask(command,
new ScheduledFutureTask<Void>(command, null,
triggerTime(delay, unit),
sequencer.getAndIncrement()));
delayedExecute(t);
return t;
}
protected <V> RunnableScheduledFuture<V> decorateTask(
Runnable runnable, RunnableScheduledFuture<V> task) {
return task;
}
private long triggerTime(long delay, TimeUnit unit) {
return triggerTime(unit.toNanos((delay < 0) ? 0 : delay));
}
private long triggerTime(long delay) {
return System.nanoTime() +
((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));
}
triggerTime 을 통해 시스템의 현재 시간 + 딜레이(나노 시간) 의 값을 가져옵니다. 너무 큰 시간일 시, overflow 방지 해서 가져오게 되어 있습니다.
ScheduledThreadPoolExecutor.ScheduledFutureTaskx
1
2
3
4
5
6
7
8
9
10
11
12
ScheduledFutureTask(Runnable r, V result, long triggerTime,
long sequenceNumber) {
super(r, result);
this.time = triggerTime;
this.period = 0;
this.sequenceNumber = sequenceNumber;
}
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
특정 시간 후에 작업할 수 있게 제공해주는 클래스입니다.
상위 클래스에서
- runnable 을 callable 로 변환
- 스레드 상태 NEW 로 지정 도 추가로 됩니다.
해당 클래스는 밑에 태스크를 실행 부분에서 좀 더 자세히 다루겠습니다.
ScheduledThreadPoolExecutor - delayedExecute if 부분
1
2
3
4
5
6
7
8
9
10
11
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);
else {
super.getQueue().add(task);
if (!canRunInCurrentRunState(task) && remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
현재 상태가 SHUTDOWN 이면 작업을 거절합니다.
ThreadPoolExecutor - isShutdown,reject
package java.util.concurrent; 에 위치한 클래스입니다. - 공식 문서
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
...
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static int ctlOf(int rs, int wc) { return rs | wc; }
public boolean isShutdown() {
return runStateAtLeast(ctl.get(), SHUTDOWN);
}
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
여기서 ctl 에 대한 설명이 주석에 정말 자세하게 되어 있습니다.
짧게 설명하면
- 29비트는 현재 시작된 스레드의 개수를 나타낸다. - wc ( WorkerCount )
- 3비트는 스레드 풀의 현재 상태를 나타낸다. - rs ( RunState ) 로 되어 있습니다.
ctl 의 숫자가 0보다 작으면 SHUTDOWN 으로 판단합니다.
1
2
3
4
5
6
7
// ThreadPoolExecutor
...
private volatile RejectedExecutionHandler handler;
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
그후 거절 핸들러가 Runnable 을 거절합니다.
ScheduledThreadPoolExecutor - delayedExecute else 부분
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);
else {
super.getQueue().add(task);
if (!canRunInCurrentRunState(task) && remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
boolean canRunInCurrentRunState(RunnableScheduledFuture<?> task) {
if (!isShutdown())
return true;
if (isStopped())
return false;
return task.isPeriodic()
? continueExistingPeriodicTasksAfterShutdown
: (executeExistingDelayedTasksAfterShutdown
|| task.getDelay(NANOSECONDS) <= 0);
}
작업 대기열에 태스크를 추가합니다. 추가할때 stop 상태이거나 주기적 작업이 아니거나 지연 시간이 지나서 즉시 실행 가능한 작업이면 참을 반환합니다.
executeExistingDelayedTasksAfterShutdown || task.getDelay(NANOSECONDS) <= 0);
executeExistingDelayedTasksAfterShutdown 은 스레드 풀이 종료되면 기존 작업들을 수행할지 안할지를 결정하는 변수입니다. ( true 이면 스레드 풀이 종료되어도 기존 작업은 실행 ) task.getDelay(…) 는 현재 작업의 System.nanoTime 과 비교해서 남은 시간을 반환해줍니다. ⭐ 작업 시간이 이전인 작업도 들어가는 이유에 해당하는 부분입니다.
ThreadPoolExecutor - ensurePrestart
해당 메소드는 무조건 하나의 스레드는 실행할 수 있게 보장 해줍니다. ( 심지어 corePoolSize 가 0이라도! )
1
2
3
4
5
6
7
8
9
10
11
12
// Same as prestartCoreThread except arranges that at least one thread is started even if corePoolSize is 0.
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
private boolean addWorker(Runnable firstTask, boolean core) {
...
}
- 현재 작업중인 스레드 ( workerCount ) 개수를 가져옵니다.
- 코어 개수보다 적으면 core 를 true 로 하고 작업을 추가합니다.
- 작업중인 스레드가 0이라면 core 를 false 로 하고 작업을 추가합니다.
ThreadPoolExecutor - addWorker
코드가 80줄 정도가 되므로 필요한 부분만 설명하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (int c = ctl.get();;) {
// Check if queue empty only if necessary.
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP)
|| firstTask != null
|| workQueue.isEmpty()))
return false;
for (;;) {
if (workerCountOf(c)
>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateAtLeast(c, SHUTDOWN))
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
... // 바로 이어서 설명
}
private boolean compareAndIncrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect + 1);
}
retry:는 java 에서 제공해주는 label 이라는 기능을 사용한 것입니다. - label 에 대해 설명한 블로그
조건문은 스레드 풀이 종료 절차에 있는 경우, 작업 큐가 비어 있는 경우 새로운 작업자를 추가하지 않도록 방지하는 역할을 합니다. 그후
- 최대 작업 개수를 넘지 않았는지 검증 -> return false
- ctl 의 숫자를 증가시키는데 성공시 -> break
- SHUTDOWN 이면 -> continue 를 합니다.
그러면 조건 다음 부분을 계속 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
private boolean addWorker(Runnable firstTask, boolean core) {
... // 조건문 부분
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (isRunning(c) ||
(runStateLessThan(c, STOP) && firstTask == null)) {
if (t.getState() != Thread.State.NEW)
throw new IllegalThreadStateException();
workers.add(w);
workerAdded = true;
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
- 워커 스레드를 생성
- 락 획득
- RUNNING 중이거나 STOP 이 아니고, 첫번재 작업이 null 일시 작업
- 작업 대기열에 추가,
workerAddedflag 참으로 변환, PoolSize 변경 - 락 해제
- 스레드 시작,
workerStartedflag 참으로 변환 - false 일 시, 실패 처리 - decrementWorkerCount, workers.remove(w), tryTerminate 호출
- 성공 여부 반환
왜 null 을 넣나요? 실행할 작업이 없으므로 start 후 바로 대기 상태로 들어갑니다. -> 작업 큐에 들어올 때 작업이 들어오면 바로 대응 ( 스레드 풀 ) ⭐ 정확한 시간에 작업을 바로 시작하기 위해 미리 준비를 하는걸로 추측합니다.
이 과정을 통해 작업 대기열에 작업을 추가 + 작업용 스레드가 대기를 합니다.
태스크가 지정된 시간에 실행
그러면 이제 이렇게 등록된 스레드가 어떻게 제 시간에 실행이 되는지 살펴보겠습니다.
ThreadPoolExecutor.runWorker
코드에서 불필요한 부분은 제거했습니다. ( 초기 작업 설정 부분, )
ThreadPoolExecutor 는 이와 같은 방식으로 주기적으로 작업을 실행시킵니다. ( TaskSchedule 에 특정된게 아닌 전체적인 ThreadPoolExecutor 를 통해 실행됩니다. )
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
try {
task.run();
afterExecute(task, null);
} catch (Throwable ex) {
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
protected void beforeExecute(Thread t, Runnable r)
protected void afterExecute(Runnable r, Throwable t)
- 처음 작업이 있거나 ( task != null ) , 가져온 작업이 있다면 ( getTask() != null )
- 스레드 풀이 STOP 일 때, 스레드가 인터럽트 상태가 아니라면 인터럽트를 통해 작업을 멈추게 한다.
- 작업이 실행 전 호출하는 메소드 - beforeExecute
- 작업 실행
- 작업 실행 후 호출하는 메소드 - afterExecute
- 완료 작업에 추가
- 워커 최후 처리 ( 스레드 풀 종료 or 작업자 제거 및 조정 )
해당 코드만 보면 어떻게 스케줄이 지정된 시간에 수행되는지 궁금하실 텐데요. getTask 부분을 통해 의도대로 태스크를 가져오게 됩니다.
ThreadPoolExecutor.getTask
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
private Runnable getTask() {
boolean timedOut = false;
for (;;) {
int c = ctl.get();
if (runStateAtLeast(c, SHUTDOWN)
&& (runStateAtLeast(c, STOP) || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
Queue 에서 작업을 가져와서 반환해줍니다. ( 불필요한 설명 생략 ) 이거만 봐도 모를텐데요. ScheduledThreadPoolExecutor 는 DelayedWorkQueue 라는 Queue 를 가지고 있습니다.
ScheduledThreadPoolExecutor.DelayedWorkQueue
작업들을 지연 시간에 따라 정렬하는 우선순위 큐를 가지고 있습니다 -> 즉, 가장 먼저 실행되어야 할 작업이 항상 큐의 앞에 위치하고 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public boolean offer(Runnable x) {
...
if (i == 0) {
queue[0] = e;
setIndex(e, 0);
} else {
siftUp(i, e);
}
...
}
private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
int parent = (k - 1) >>> 1;
RunnableScheduledFuture<?> e = queue[parent];
if (key.compareTo(e) >= 0)
break;
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
}
시간에 따라 siftUp , siftDown 을 통해 우선순위를 보장합니다.
ScheduledThreadPoolExecutor.ScheduledFutureTask
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public int compareTo(Delayed other) {
if (other == this) // compare zero if same object
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
}
작업의 시간을 통해 정렬을 가능하게 해줍니다.
ScheduledThreadPoolExecutor.poll
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public RunnableScheduledFuture<?> poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
RunnableScheduledFuture<?> first = queue[0];
return (first == null || first.getDelay(NANOSECONDS) > 0)
? null
: finishPoll(first);
} finally {
lock.unlock();
}
}
private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {
int s = --size;
RunnableScheduledFuture<?> x = queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
setIndex(f, -1);
return f;
}
첫번째 작업의 시간이 아직 남았다면 ( first.getDelay(NANOSECONDS) > 0) null 을 반환 아니면, 큐를 재조정하고 반환합니다.
이전 시간의 작업은 당연히 맨 처음에 위치하고 + getDelay 가 0보다 작을것 입니다. 그렇기에 작업이 바로 실행되게 됩니다.
결론
이와같은 과정을 거쳐 지정된 시간에 태스크 작업이 수행됩니다.


이를 가능하게 해주는 기능으로
- ThreadPoolExecutor 의 주기적 수행
ReentrantLock를 통한 Locking
등이 있겠습니다. 온전히 자바의 클래스들을 통해 수행하는게 스프링의 의의 ( POJO ) 에 맞게 잘 구현되어 있습니다. 이상으로 긴 탐구글을 마치겠습니다. 감사합니다!